This vignette demonstrates the step-by-step FFdownload()
workflow — browse available datasets, download, and process separately —
using xts as the output format. This separation is valuable
for reproducible research: you can save a dated snapshot of the raw zip
files and re-process them at any time without re-downloading.
For a simpler one-step approach (especially for interactive use), see
vignette("FFD-tibble-how-to") and the FFget()
function.
library(FFdownload)
outd <- paste0("data/", format(Sys.time(), "%F_%H-%M"))
outfile <- paste0(outd, "FFData_xts.RData")
listfile <- paste0(outd, "FFList.txt")Step 1: Browse available datasets
Option A — FFlist() (recommended, new in v1.2.0)
FFlist() returns a tidy data frame that you can filter
directly:
Option B — listsave (classic approach, still
supported)
FFdownload(exclude_daily=TRUE, download=FALSE, download_only=TRUE, listsave=listfile)
#> Step 1: getting list of all the csv-zip-files!
read.delim(listfile, sep=",")[c(1:4, 73:74), ]
#> X x
#> 1 1 F-F_Research_Data_Factors_CSV.zip
#> 2 2 F-F_Research_Data_Factors_weekly_CSV.zip
#> 3 3 F-F_Research_Data_Factors_daily_CSV.zip
#> 4 4 F-F_Research_Data_5_Factors_2x3_CSV.zip
#> 73 73 F-F_Momentum_Factor_CSV.zip
#> 74 74 F-F_Momentum_Factor_daily_CSV.zipStep 2: Download selected datasets
inputlist <- c("F-F_Research_Data_Factors_CSV","F-F_Momentum_Factor_CSV")
FFdownload(exclude_daily=TRUE, tempd=outd, download=TRUE, download_only=TRUE, inputlist=inputlist)
#> Step 1: getting list of all the csv-zip-files!
#> Step 2: Downloading 2 zip-files
list.files(outd)
#> [1] "F-F_Momentum_Factor_CSV.zip" "F-F_Research_Data_Factors_CSV.zip"The action parameter (new in v1.2.0) is equivalent and
more readable:
FFdownload(exclude_daily=TRUE, tempd=outd, action="download_only", inputlist=inputlist)The cache_days parameter prevents re-downloading files
that are already fresh:
# Reuse any cached file younger than 7 days; only download if stale
FFdownload(exclude_daily=TRUE, tempd=outd, action="download_only",
inputlist=inputlist, cache_days=7)Step 3: Process downloaded files
FFdownload(exclude_daily=TRUE, tempd=outd, download=FALSE, download_only=FALSE,
inputlist=inputlist, output_file=outfile)
#> Step 1: getting list of all the csv-zip-files!
#> Step 3: Start processing 2 csv-files
#> | | | 0% | |=================================== | 50% | |======================================================================| 100%
#> Be aware that as of version 1.0.6 the saved object is named FFdata rather than FFdownload to not be confused with the corresponding command!To also get the data back directly (skipping a separate
load() call), add return_data=TRUE:
FFdata <- FFdownload(exclude_daily=TRUE, tempd=outd, download=FALSE,
download_only=FALSE, inputlist=inputlist,
output_file=outfile, return_data=TRUE)To replace French’s missing-value sentinels (-99,
-999, -99.99) with NA during
processing:
FFdownload(exclude_daily=TRUE, tempd=outd, download=FALSE, download_only=FALSE,
inputlist=inputlist, output_file=outfile,
na_values=c(-99, -999, -99.99))Step 4: Inspect the result
load(outfile)
ls.str(FFdata)
#> x_F-F_Momentum_Factor : List of 3
#> $ annual :List of 1
#> $ monthly:List of 1
#> $ daily : Named list()
#> x_F-F_Research_Data_Factors : List of 3
#> $ annual :List of 1
#> $ monthly:List of 1
#> $ daily : Named list()The output is a named list. Each element corresponds to one dataset
and contains three sub-lists: $monthly,
$annual, and $daily. Within each sub-list,
sub-tables are named after the section headings in French’s CSV. When a
section has no heading the name defaults to Temp1,
Temp2, etc. — in factor files the main returns table is
always Temp2.
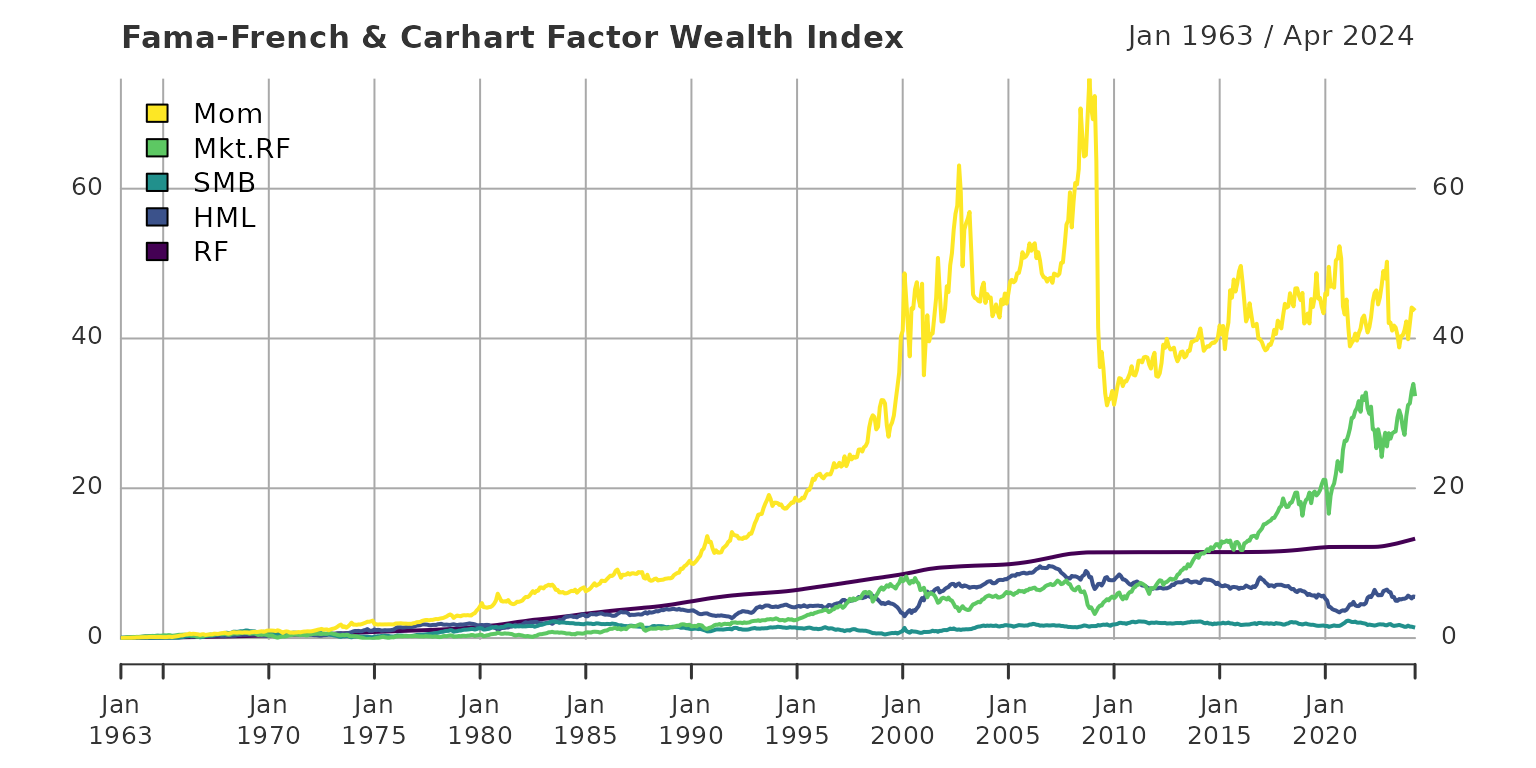
Step 5: Use the data
Code below merges all monthly xts objects, trims to
post-1963, and plots cumulative wealth indices (credit: Joshua
Ulrich):
monthly <- do.call(merge, lapply(FFdata, function(i) i$monthly$Temp2))
monthly_1963 <- na.omit(monthly)["1963/"]
monthly_returns <- cumprod(1 + monthly_1963 / 100) - 1
plot(monthly_returns)